
Unlocking cultural content using AI

At Whereverly, we believe that cultural audio content is one of the most powerful tools that can be used to give a visitor a sense of place and understand a destination’s culture. That’s why we have collected over 100 hours of cultural audio, including local stories, poems, and music to deliver to our users through our apps.
One limitation to simple audio content, however, is that it is inaccessible to wide range of our users, such as those who are hard of hearing, or non-English speakers who may struggle understanding strong regional accents. Audio therefore requires transcriptions to ensure accessibility to all – but how can this be achieved in the most successful and sustainable way? For the last few years, we’ve been on a mission to find out and are excited to now share our story of how we are using AI to make our cultural audio accessible to everyone.
From frustrating beginnings
When first diving into the world of transcription services, we immediately noticed two barriers to our successful implementation of them. The first was cost and the second was quality. With manual transcription, we estimated the costs to transcribe our entire catalogue would be between £6,000 and £24,000 – a sum that would be not only unsustainable for us a business, but for our clients also.
Automated transcription services such as those provided by Amazon Web Services (AWS) or Google Cloud Platform (GCP) also left us disappointed. If we fed either of these services neutral accents, the results were acceptable, but any hint of a strong regional accent and it started to fall apart. These services may have improved but the results soured us enough to put automated translation on the back burner.
Enter AI
Our scepticism around automated transcription was still firmly in place when OpenAI released its Whisper project which is a general-purpose speech recognition AI model. Having been trained on over 600,000 hours of data collected from the web, we felt confident giving it a go. We fed Whisper our trickiest audio story, and the results blew us away!
Not only were the results impressive, but Whisper being released as an open-source project also gave us flexibly on how we integrated it into our workflow.
From here, with a bit of digital plumbing we have been able to integrate Whisper transcriptions into our audio publishing workflow. As soon as a client uploads a new audio file into the system, transcriptions are automatically created for review and approval. Our process is not only cost effective but generates quick and accurate transcriptions.
Psst! For those interested in the more technical details, you can check out ‘the nitty gritty’ below.
The end result
We have had our transcription process in place for several months now and we have been slowly transcribing our library of audio content. Soon, audio content on all 12 of our apps will be accessible to users in both audio and text format, unlocking the local culture of our destinations to all. It’s clear that, while still in its infancy, AI technology is already providing substantial benefits for us and our clients. We are excited to continue exploring and working alongside it to unlock its potential in the travel-tech sector in the future.
The nitty gritty
Our high level architecture and data flow is outlined below:
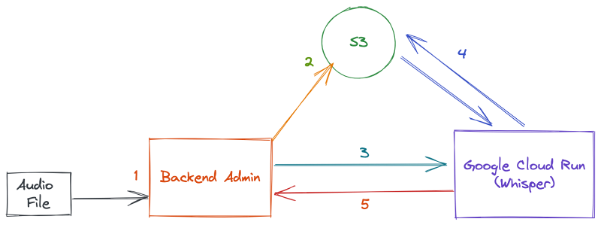
- We had an existing Symfony backend admin service which handled the uploading, processing, and storage of our audio files.
- The output from the backend admin is several audio files (we generate an HLS stream and a M4A file) that are stored in S3 for public consumption by our apps.
- We updated our backend service so that once the files are uploaded to S3 we make a HTTP request to a Whisper transcription service that we host on Google Cloud Run.
- The Whisper service downloads the audio files from S3 that were previously generated from our backend admin, and it starts the transcription process.
- Once the Whisper service has completed its transcription it then makes a HTTP request back to the backend admin which stores the newly generated transcript.
Choosing something like Google Cloud Run to host our Whisper AI model may sound strange, as it does not provide any sort of AI acceleration to speed up the transcription process, instead relying solely on the CPU. As our transcription process is not time sensitive, we don’t necessarily care about performance. Instead, we valued Google Cloud Run’s easy ability to ‘scale to zero’. By scaling to zero, when no transcription process is running, we have no running container instances and our Cloud Run hosting costs drop to £0.
Next, we will peak inside our Whisper service and look at it in a bit more detail.
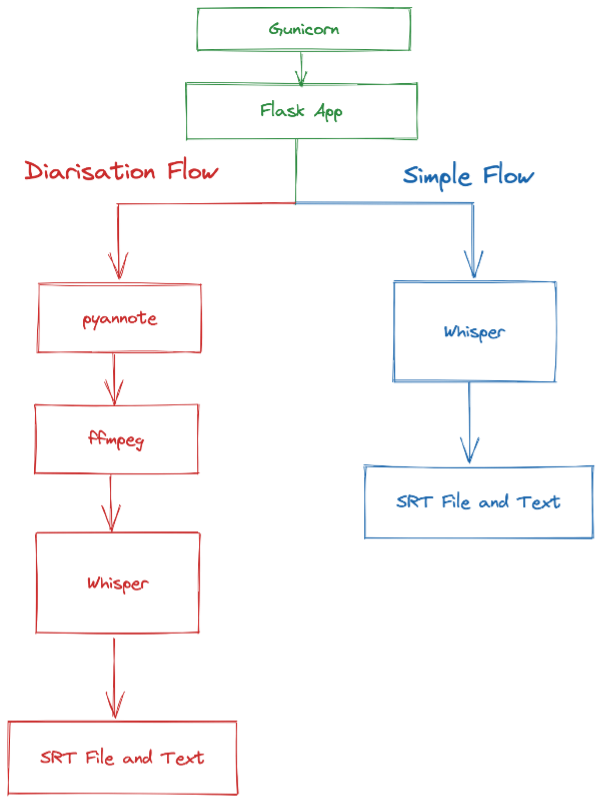
At the frontend of the Whisper service is a standard Gunicorn and Flask app which handles the HTTP layer and some simple logic. At this point we either we head down the “Simple Flow” or the more complicated “Diarisation Flow”.
The “Simple Flow” takes the audio file we generated from backend service and passes it into Whisper which then produces a SRT (subtitle) file and the raw text transcript. This information is then passed back to the backend service for it to store.
Diarisation
The “Diarisation Flow” is slightly more complicated. Speaker diarisation is the process of breaking down audio into segments according to the identity of each speaker. This is useful when we have multiple speakers in a story, and we want to identify them separately.
To perform diarisation we use pyannote which is another open-source AI project. The output of pyannote looks something like this:
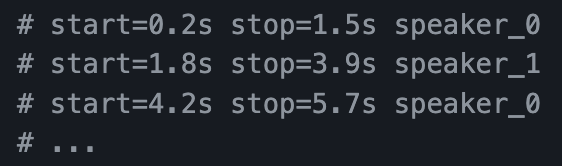
We take the output from pyannote and then use ffmpeg to split our audio file into chunks. So, using the above example we would export 3 separate audio files, 1 file from 0.2s to 1.5s, another from 1.8s to 3.9s and a final file starting at 4.2s and ending at 5.7s.
These separate files are then passed into Whisper to produce small transcripts from each chunked audio file.
We finally join each of these chunked transcripts back together to product a SRT (subtitle) file and a raw text transcript.
We can’t claim that this is a brand new approach and we used this notebook as inspiration.